Representation Learning with Contrastive Predictive Coding (CPC)
Abstract
지도 학습(supervised learning)은 다양한 응용에서 좋은 성능을 보이지만, 비지도 학습(unsupervised learning)은 광범위한 활용이 어려움.
해당 논문에서는 Contrastive Predictive Coding (CPC)이라는 새로운 비지도 학습법을 제안함. 이 방법은 autoregressive 모델을 사용하여 latent space에서의 미래를 예측함으로서 유용한 표현을 학습함.
CPC는 확률적 대조 손실(probabilistic contrastive loss)를 사용하여, 미래를 예측하기에 유용한 정보를 latent representation에 담도록 유도하고, negative sampling을 통해 효율적으로 학습함.
CPC는 모달리티에 구애받지 않고 이미지, 오디오, 비디오 등 다양한 데이터에 대해 우수한 성능을 보임.
Introduction
딥러닝의 최근 발전은 지도 학습(supervised learning)에 크게 의존하고 있음. 레이블 된 데이터를 활용해 end-to-end로 학습하여, 수작업으로 설계하는 feature extractor를 대체함.
하지만, 딥러닝은 대량의 레이블 된 데이터가 필요하고, 레이블 된 데이터가 있다고 해도 하나의 태스크에만 최적화된 모델이 되어 일반화가 어렵다는 단점이 있음. 예를 들어, 이미지 분류 모델은 이미지 분류 태스크에 최적화되어 있지만, 다른 태스크(예: 이미지 캡셔닝)에는 잘 작동하지 않음.
비지도 학습은 라벨 없이 데이터의 구조를 학습함으로서 더 범용적이고 견고한 표현을 만들 수 있게함.
이 논문에서는 다음의 세 가지 주요 아이디어를 통해 비지도 학습을 위한 새로운 방법인 Contrastive Predictive Coding (CPC)을 제안함:
- 고차원 입력 데이터를 저차원 잠재 공간(latent space)으로 매핑하여, 입력 데이터의 구조를 학습함.
- autoregressive 모델을 사용하여 잠재 공간에서의 미래를 예측함으로서 유용한 표현을 학습함.
- Noise-Contrastive Estimation (NCE) 기반의 확률적 대조 손실(probabilistic contrastive loss)을 사용하여, 예측된 표현이 실제와 유사하도록 유도함.
Contrastive Predictive Coding
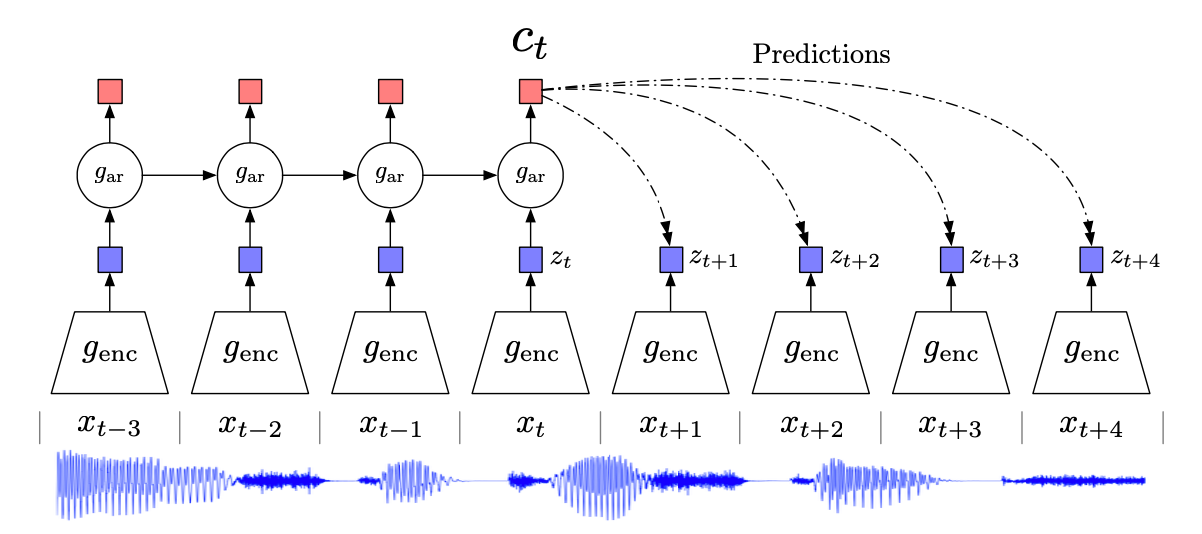
Motivation and Intuitions
이 구조의 핵심 아이디어는 high-dimensional 입력 신호에서 서로 다른 부분끼리 공유되는 정보를 학습하는 것임.
음성이나 이미지 같은 정보는 high-dimensional 데이터로서, 노이즈를 포함한 많은 정보를 갖고있음. 기존의 접근법은 가려진 원본 데이터를 직접 복원하거나 생성하려고 시도하지만, 이는 계산이 비효율적이고 모델 용량이 낭비되며 중요한 의미 정보가 희석됨.
예를 들어, 파형 신호로부터 음성 신호를 복원하려고 할 때, 파형의 모든 세부 사항을 복원하는 것은 음소, 억양 등을 분석하려고 할 때 불필요한 노이즈를 많이 포함하게 됨.
CPC는 미래의 입력값 $x$와 문맥 $c$가 공유하는 정보에만 집중하도록 함. 그래서 입력과 문맥을 각각 처리해 그들 사이의 mutual information을 최대화하는 것을 목표로 함.
- $I(x; c)$: $x$와 $c$ 사이의 mutual information
- $p(x, c)$: $x$와 $c$의 joint probability distribution
$p(x c)$: $c$가 주어졌을 때 $x$의 conditional probability distribution - $p(x)$: $x$의 marginal probability distribution
$x$와 $c$가 공유하는 의미 정보를 최대한 보존하는 방식으로 학습하겠다는 것임.
Contrastive Predictive Coding
CPC는 다음과 같은 세 부분으로 구성됨:
- Encoder: 입력 신호 $x_t$를 압축 잠재 공간으로 매핑하는 encoder $g_{\text{enc}}$를 사용함. 이 encoder는 입력 신호의 구조를 학습함.
- Autoregressive Model: 잠재 공간에서의 미래를 예측하는 autoregressive 모델 $g_{\text{ar}}$를 사용함. 이 모델은 이전의 잠재 벡터들을 입력으로 받아 문맥을 생성함. 이 문맥은 미래의 잠재 벡터를 예측하는 데 사용됨.
- Predict: 앞서 언급했듯이, CPC는 $c_t$로부터 직접 $x_{t+k}$를 예측하지 않고, $c_t$와 $z_{t+k}$ 사이의 score를 계산.
이 score는 $c_t$와 $z_{t+k}$ 사이의 유사성을 나타내며, 이를 통해 미래의 잠재 벡터를 예측함.
$f_k$는 다음과 같은 log-bilinear 모델로 정의됨:
\[f_k(x_{t+k}, c_t) = \exp(z_{t+k}^T W_k c_t)\]여기서 $W_k$는 time step $k$에 대한 가중치 행렬임. 즉, 각 time step에 대해 문맥 벡터 $c_t$로부터 $z_{t+k}$를 직접 복원하려 하지 않고, 문맥 벡터와 잠재 벡터 사이의 유사성을 측정함.
$p(x)$나 $p(x|c)$를 직접 계산하는 것이 아니라, 샘플링을 통해 대조 학습을 수행함. 즉, 정답 $x_{t+k}$와 여러 개의 negative sample들로부터 $f_k$를 계산하여, 정답의 score는 높이고 negative sample의 score는 낮추도록 학습함.
해당 구조로부터 현재 시점의 잠재 벡터 $z_t$와 과거 문맥을 포함하는 문맥 벡터 $c_t$ 두가지의 표현을 학습하게 되는데, 두 표현 모두 downstream 태스크에 사용 가능함.
예를 들어, 음성 인식 태스크에서 특정 위치의 음소를 예측하는 데에는 $z_t$를 사용하고, 전체 음성 신호를 인식하는 데에는 $c_t$를 사용할 수 있음.
CTC는 프레임워크이므로, 특정 모델 구조에 구애받지 않음. 해당 논문에서는 인코더로 stride CNN + ResNet block을 사용하고, autoregressive 모델로는 GRU를 사용하였지만, 이론적으로 Transformer나 다른 모델 구조도 사용 가능함.
InfoNCE Loss and Mutual Information Estimation
CPC의 목표는 $c_t$와 $z_{t+k}$ 사이의 Mutual Information을 최대화하는 것임. Mutual Information은 다음과 같이 정의됨:
\[I(x; c) = \sum_{x, c} p(x, c) \log \frac{p(x|c)}{p(x)} = \mathbb{E}_{p(x, c)} \left[ \log \frac{p(x|c)}{p(x)} \right]\]즉, 문맥 $c$가 주어졌을 때, 미래 $x$의 확률 분포가 얼마나 잘 예측되는지를 측정함.
이 Mutual Information를 직접 계산하는 것은 복잡하고, 이 논문의 목적도 아니기 때문에 대신 InfoNCE Loss를 사용하여 근사함. InfoNCE Loss는 다음과 같이 정의됨:
Loss Derivation
| $f(x_{t+k}, c_t)$는 $\frac{p(x_{t+k} | c_t)}{p(x_{t+k})}$의 근사값이므로, optimal한 loss는 다음과 같이 정리됨 |
따라서 다음과 같은 관계식 성립:
\[I(x_{t+k}; c_t) \geq \log N - \mathcal{L}_{N}\]즉, $\mathcal{L}{N}$를 최소화하면 $I(x{t+k}; c_t)$의 하한을 최대화할 수 있음.
Related Work
CPC의 핵심 아이디어 두 가지는
- Predictive coding: 입력 신호로부터 미래를 예측하여 정보를 학습
- Contrastive learning: positive sample과 negative sample을 비교해 정보를 구별
이 두 가지 아이디어는 각각 따로 사용되어왔으나, CPC는 이 두 가지를 통합해 정보량을 최대화할 수 있는 방법으로 연결함.
Contrastive loss 기반 방법들
- Triplet loss:
예: FaceNet, metric learning 등
정답 쌍(anchor–positive)과 부정 쌍(anchor–negative)을 멀어지게 하는 방식 - Time-Contrastive Networks (TCN) [Sermanet et al.]:
비디오 내 다른 시간의 장면들을 서로 구분
서로 다른 시점의 표현을 멀리 떨어뜨리도록 학습 - Time-Contrastive Learning (Hyvärinen):
시간 분할로 생성한 구간을 분류하는 contrastive 학습
Independent Component Analysis(ICA) 기반으로도 사용
Predictive modeling 기반 방법들
Word2Vec [Mikolov et al.]:
주변 단어 예측 (Skip-gram, CBOW)
사실상 단어 간 mutual information을 학습하는 구조Skip-thought vectors [Kiros et al.]:
한 문장을 보고 다음 문장을 예측
LSTM 기반의 문장 수준 모델Byte mLSTM [Radford et al.]:
글자 수준의 RNN을 이용해 다음 토큰 예측
대규모 unsupervised language modelComputer Vision 분야:
- Colorization [Zhang et al.]: 회색 이미지로부터 색상 복원
- Patch position prediction [Doersch et al.]: 이미지 조각의 상대적 위치 예측
- Jigsaw puzzle [Noroozi et al.]: 이미지 조각 재배열 예측
Experiments
Audio
- 데이터셋: LibriSpeech (100시간)
- 입력: 16kHz 오디오 파형
- 인코더: strided CNN
- 오토리그레서: GRU
- 예측: 12 step 미래 예측 (1 step ≈ 10ms)
평가: latent 벡터를 음소 분류와 화자 분류 태스크에 사용하여 성능 평가
- 분류 정확도
| 방법 | 음소 분류 (%) | 화자 분류 (%) |
|---|---|---|
| 무작위 init | 27.6 | 1.87 |
| MFCC | 39.7 | 17.6 |
| CPC (linear) | 64.6 | 97.4 |
| Fully supervised | 74.6 | 98.5 |
MFCC 등의 전통적 방법과 비교하여 높은 성능을 보였고, supervised 방법과 비교해도 큰 차이가 없음.
- Negative Sampling 전략
| 전략 | 음소 정확도 (%) |
|---|---|
| Mixed speaker | 64.6 |
| Same speaker | 65.5 |
| Exclude same sequence | ↓ 57.3 |
| Only current sequence | 65.2 |
negative sample끼리 서로 너무 다르면 학습이 잘 되지 않음. 같은 화자 안에서 구별하는 것이 학습에 더 효과적임.(적당히 유사한 negative sample이 필요함)
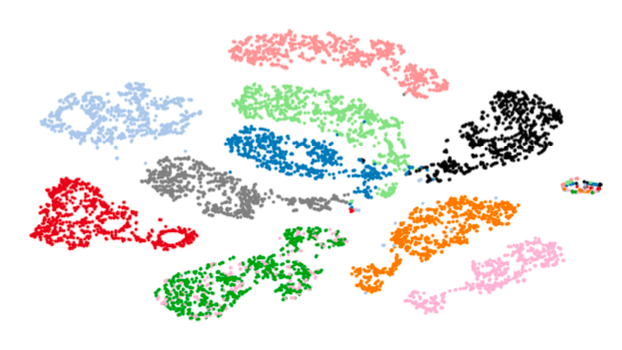
위 사진은 CPC로 학습한 화자 표현을 t-SNE로 시각화한 것임. 서로 다른 화자들이 잘 구분되는 것을 확인할 수 있음.
Vision
- 데이터셋: ImageNet(ILSVRC, 이미지 분류 데이터셋)
- 입력: 300x300 이미지를 256x256로 무작위 크롭
- 인코더: ResNet v2-101
- 오토리그레서: PixelCNN
- 예측: 각 row에서 다음 row의 latent 벡터를 예측
평가: latent 벡터를 이미지 분류 태스크에 사용하여 성능 평가
- 분류 정확도(Top-1 accuracy)
| 방법 | Top-1 정확도 (%) |
|---|---|
| Video (Wang & Gupta) | 29.8 |
| Relative Position (Doersch) | 30.4 |
| BiGAN | 34.8 |
| Colorization (Zhang et al.) | 35.2 |
| Jigsaw (Noroozi & Favaro) | 38.1 |
| Motion Segmentation (Doersch) | 27.6 |
| Exemplar | 31.5 |
| Relative Position (ResNet) | 36.2 |
| Colorization (ResNet) | 39.6 |
| CPC (ResNet v2-101) | 48.7 |
- 분류 정확도(Top-5 accuracy)
| 방법 조합 (ResNet 기반) | Top-5 정확도 (%) |
|---|---|
| Motion Segmentation | 48.3 |
| Exemplar | 53.1 |
| Relative Position | 59.2 |
| Colorization | 62.5 |
| MS + Ex + RP + Colorization | 69.3 |
| CPC | 73.6 |
CPC는 다른 모든 self-supervised 방법들보다 높은 성능을 보임. 심지어 다른 4개 self-supervised 방법들을 조합한 것보다도 높은 성능을 보임.
Natural Language
- 데이터셋: BookCorpus (영어 소설 데이터셋)
- 입력: 문장 단위로 분할
- 인코더: 1D Convolution -> ReLU -> Mean Pooling
- 오토리그레서: GRU
- 예측: 현재 문장을 기반으로 다음 문장들(최대 3개)의 latent 벡터를 예측
- 평가: latent 벡터를 문장 분류 태스크에 사용하여 성능 평가
- 평가 데이터셋:
- MR: 영화 리뷰 감성 분류
- CR: 상품 리뷰 감성 분류
- SUBJ: 주관적/객관적 문장 분류
- MPQA: 의견 극성 분류
- TREC: 질문 유형 분류
- 평가 데이터셋:
- 문장 분류 정확도
| 방법 | MR | CR | Subj | MPQA | TREC |
|---|---|---|---|---|---|
| Paragraph Vector | 74.8 | 78.1 | 90.5 | 74.2 | 91.8 |
| Skip-thought (2015) | 75.5 | 79.3 | 92.1 | 86.9 | 91.4 |
| Skip-thought + LN | 79.5 | 82.6 | 93.4 | 89.0 | — |
| CPC | 76.9 | 80.1 | 91.2 | 87.7 | 96.8 |
복잡한 decoder 구조 없이 skip-thought보다 좋은 성능을 보임. 특히 TREC 태스크에서 높은 성능을 보임.
Reinforcement Learning
에이전트가 관측만으로 더 좋은 표현을 학습할 수 있도록, CPC를 보조 손실로 사용함.
- 환경: DeepMind Lab(3D 환경에서 움직이며 목표를 찾는 게임)
- 태스크:
rooms_watermaze: 미로에서 목표를 찾는 태스크explore_goal_locations_small: 여러 후보 위치에 대해 목표 위치를 탐색하는 태스크seekavoid_arena_01: 장애물을 피하며 보상을 찾아다니는 태스크lasertag_three_opponents_small: 아레나에서 3명의 상대와 레이저 태그를 하는 태스크rooms_keys_doors_puzzle: 열쇠와 문을 이용해 정해진 순서대로 퍼즐을 푸는 태스크
- 기본 에이전트: A2C(Advantage Actor-Critic)
- 기존 구조:
- 관측: RGB 이미지
- 인코더: CNN(관측 정보 처리), LSTM(시간 정보 처리)
- 정책: MLP
- 가치 함수: MLP
- CPC 구조:
- 기존 인코더 구조를 유지하고, 출력 위에 CPC 구조를 추가해 미래 latent 벡터를 예측하도록 함.
손실: 기존 Policy Loss에 CPC Loss를 추가하여, 에이전트가 더 유용한 표현을 학습하도록 유도함.
- 성능 비교
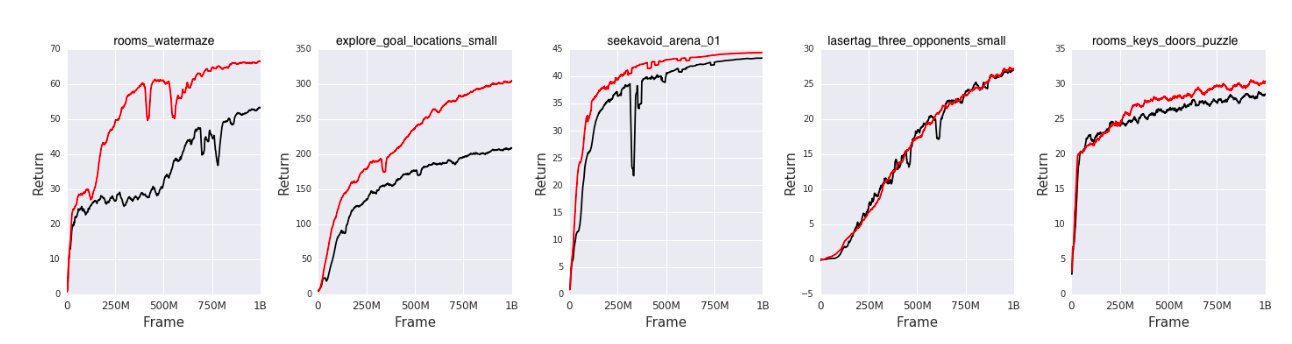
.
기존 A2C 구조에 CPC를 추가한 경우, 모든 태스크에서 성능이 향상됨. 특히 rooms_watermaze와 explore_goal_locations_small 태스크에서 큰 성능 향상을 보임.
lasertag_three_opponents_small 태스크는 메모리 의존도가 거의 없는 단순한 태스크이므로, CPC의 효과가 크지 않음.
Conclusion
Contrastive Predictive Coding(CPC)는 입력 데이터를 잠재 표현으로 인코딩한 후, 오토리그레시브 모델로 문맥을 요약하고, 미래 표현을 예측하는 self-supervised 학습 방식으로, 이를 Noise Contrastive Estimation 기반의 InfoNCE 손실로 학습함으로써 mutual information의 하한을 최대화한다. 이 간단한 프레임워크는 복잡한 복원 없이도 의미 있는 정보를 추출할 수 있으며, 오디오, 이미지, 자연어, 강화학습 등 다양한 도메인에 적용되어 기존 self-supervised 방법들을 능가하는 표현 성능을 보여주었다.