Sequence to Sequence Learning with Neural Networks - 논문 리뷰
0. Abstract
Deep Neural Network(DNN)은 어려운 학습 작업에서 뛰어난 성능을 보이지만, 시퀀스를 시퀀스로 매핑하는데 한계가 있다. 해당 연구에서는 시퀀스 구조에 대한 최소한의 가정만으로 작동하는 일반적인 시퀀스 학습 방법을 제안한다.
이 방법은 다층 LSTM을 사용해 입력 시퀀스를 고정 차원의 벡터로 매핑하고, 이를 기반으로 출력 시퀀스를 디코딩한다. 이 방법으로 WMT’14 데이터셋의 영어-프랑스어 번역 작업에서 LSTM 모델이 BLEU 점수 34.8을 기록, 기존 SMT(통계적 기계 번역) 시스템(BLEU 33.3)을 능가했다. SMT 시스템에 의해 생성된 문장들을 LSTM 모델로 리랭킹했을 때에는 SOTA(BLEU 37.0)에 가까운 성능(BLEU 36.5)을 얻었다.
긴 문장에서도 성능이 우수하며, 단어 순서를 역전시키는 데이터 전처리로 성능을 크게 개선했다. 추가적으로, source sequence의 입력 순서를 뒤집었을 때 LSTM의 성능이 향상되는 것을 발견했다.
1. Introduction
DNN(심층신경망)은 이미지 분류와 같은 어려운 문제에서 탁월한 성능을 보이고 복잡한 계산을 할 수 있는 모델이지만, 고정된 차원의 입력과 출력을 처리하도록 설계되었기 때문에 가변적인 길이의 시퀀스를 다루는 문제에는 부적합하다.
본 연구에서는 이러한 한계점을 극복하기 위해 두개의 LSTM 아키텍쳐를 사용한다.
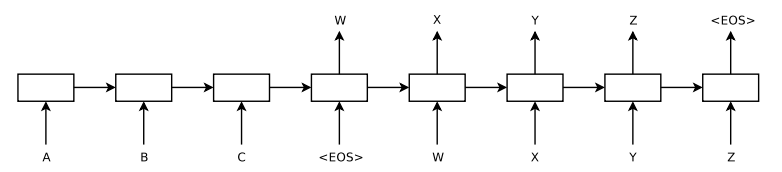
첫번째 LSTM 모델은 입력 시퀀스를 한 단계씩 처리하며 고정 차원의 벡터 표현으로 인코딩한다.(Encoder) 둘째 LSTM 모델은 인코딩된 벡터를 기반으로 출력 시퀀스를 디코딩한다.(Decoder)
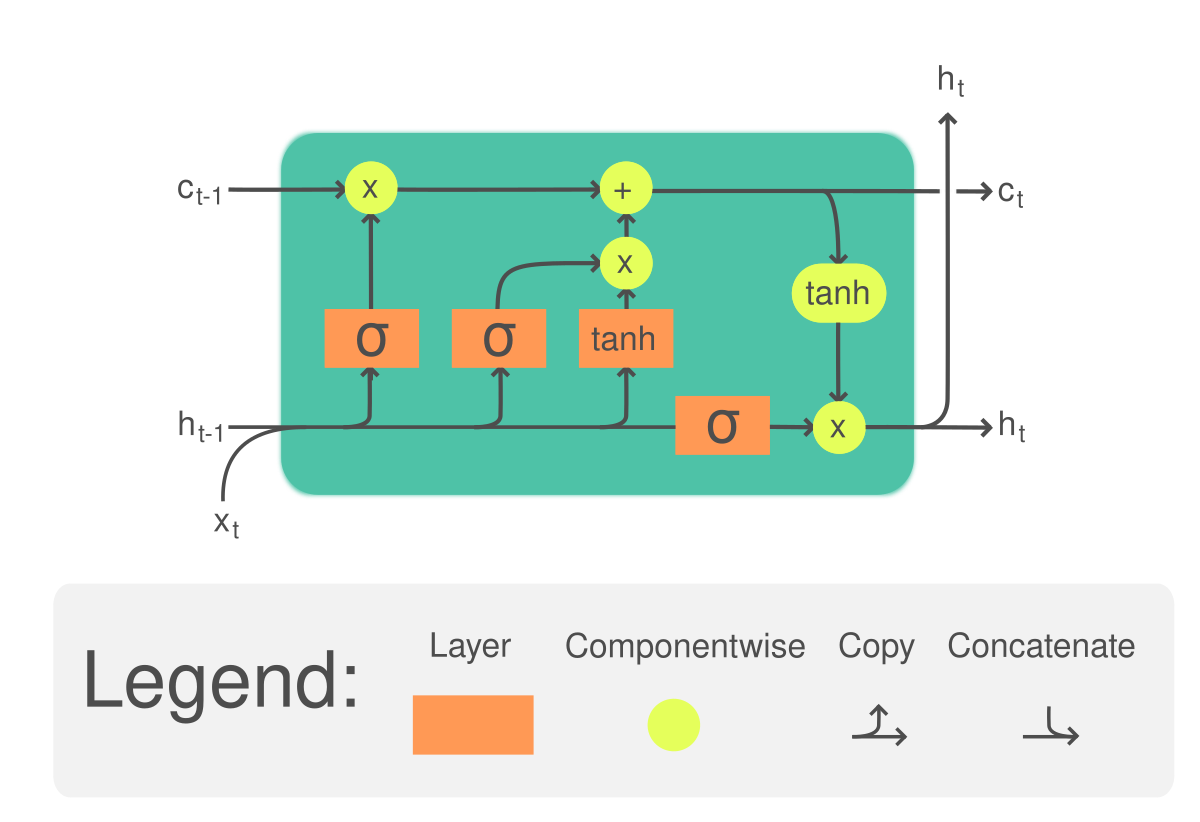
LSTM은 장기 의존성을 처리할 수 있어 입력과 출력간 시간 차이가 큰 경우에도 적합하다.
2. Model
이 논문에서는 Recurrent Neural Network (RNN)의 일반적인 확장인 Long Short-Term Memory (LSTM)를 사용하여 시퀀스를 시퀀스로 매핑하였다. LSTM의 장기 의존성 처리 능력을 통해 RNN 구조보다 더 좋은 성능을 보일 수 있었다.
제안된 모델은 입력 시퀀스를 고정된 크기의 벡터 표현으로 변환하는 인코더(Encoder)와 이 벡터를 기반으로 출력 시퀀스를 생성하는 디코더(Decoder)로 구성되었다.
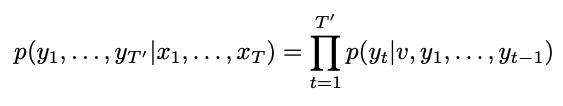
모델의 목표는 조건부 확률 $p(y1,…,yT′∣x_1,…,x_T)$을 계산하는 것이고, 이를 위해 인코딩 과정에서 입력 시퀀스 $(x_1,x_2,…,x_T)$를 순차적으로 처리하여 고정 차원의 벡터 표현 $v$를 생성한다.
인코더에서 생성된 vector $v$를 초기 은닉 상태로 설정 후, 디코더를 사용해 출력 시퀀스 $(y_1,y_2,…,y_T)$를 생성한다. 이때 각 시간 단계 $t$에서 출력 단어 $y_t$는 $p(y_t∣v,y_1,…,y_{t−1})$로 계산하는데, 소프트맥스 함수를 사용하여 $y_t$를 선택한다
이 모델은 LSTM은 장기 의존성을 처리할 수 있어 입력과 출력 시퀀스 간의 복잡한 관계를 학습 가능하고, 모든 출력 시퀀스는 끝에 종료 토큰(EOS)을 추가하여 출력 길이를 동적으로 조절할 수 있다. 인코더와 디코더에 각각 별도의 LSTM 사용해 매개변수 수를 증가시키고 다중 언어 학습이 가능하다.
이 연구에선 LSTM을 여러 층으로 구성해 성능을 개선했는데, 4개 층을 사용해 얕은 LSTM 대비 성능 향상을 확인했다. 또한 입력 시퀀스를 거꾸로 입력하는 전처리를 진행했는데, 성능의 큰 향상을 확인하였다, 입력의 첫 단어가 출력의 첫 단어와 가까워지며(e.g. 사랑해 너를 나는 → I love you) 학습이 쉬워졌다는 분석이었다.
3. Experiments
실험의 목표는 제안된 LSTM 모델의 성능을 기계 번역 작업(WMT’14 영어-프랑스어 번역 데이터셋)에서 평가하는 것이고, 다음 두 가지 방법으로 테스트하였다.
- LSTM으로 입력 문장을 직접 번역.
- 기존 통계적 기계 번역(SMT) 시스템의 후보 번역(1000-best lists)을 재정렬(rescoring).
데이터셋
- WMT’14 영어-프랑스어 번역 데이터셋:
- 약 1200만 개의 문장으로 구성된 병렬 코퍼스.
- 소스 언어(영어)와 타겟 언어(프랑스어)의 단어 수: 각각 3억 4천만, 3억 4백만 단어.
- 사전 크기:
- 영어: 상위 16만 개 단어.
- 프랑스어: 상위 8만 개 단어.
- 사전 외(out-of-vocabulary, OOV) 단어는 “UNK” 토큰으로 대체.
디코딩 및 재정렬
- 디코딩(Decoding):
- LSTM의 출력 확률을 기반으로 번역 생성.
- 빔 서치(Beam Search) 기법을 사용해 최적의 번역 선택:
- 빔 크기: 1~12로 실험.
- 빔 크기 2에서 대부분의 성능 향상이 발생.
- 재정렬(Rescoring):
- 기존 SMT 시스템이 생성한 1000-best 후보 리스트를 LSTM으로 다시 평가.
- LSTM 점수와 SMT 점수를 결합해 최적의 번역 선택.
입력 시퀀스 역전(Reversing Input Sentences)
- 입력 문장의 단어 순서를 뒤집는 전처리 기법이 큰 성능 향상을 가져옴.
- BLEU 점수: 25.9 → 30.6.
- 원인: 역전 처리로 입력과 출력 사이의 단기 의존성(short-term dependencies)이 강화되어 학습이 쉬워짐.
모델 학습 및 병렬화
- 학습 설정:
- 심층 LSTM(4개 층), 각 층에 1000개의 유닛 사용.
- 매개변수: 약 3억 8400만 개.
- 학습:
- 학습률: 0.7로 시작, 5 epoch 이후 절반씩 감소.
- 배치 크기: 128.
- 그래디언트 폭발 방지(Gradient Clipping): 그래디언트의 L2 노름이 5를 넘지 않도록 제한.
- 병렬화(Parallelization):
- 8개의 GPU를 사용하여 병렬 처리.
- 4개의 GPU: LSTM 층별로 사용.
- 4개의 GPU: 출력 소프트맥스 연산에 활용.
- 결과적으로 약 6300 단어/초 처리 속도 달성.
실험 결과
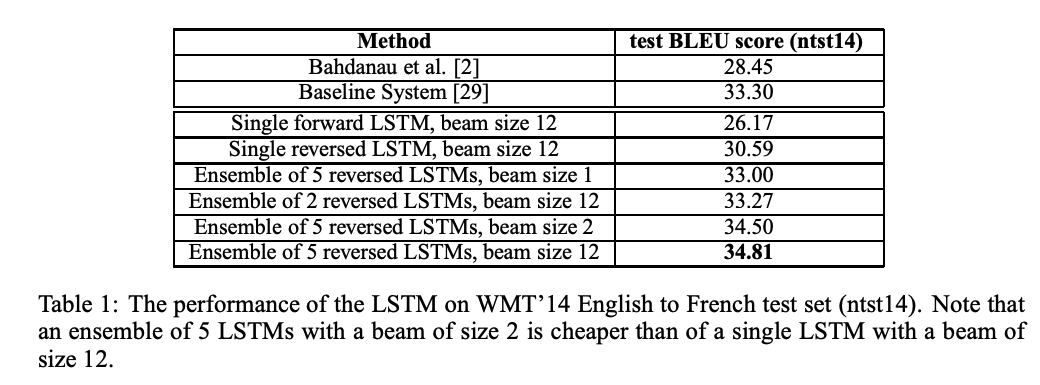

- 직접 번역(Direct Translation):
- 앙상블(5개 LSTM 모델) 사용 시 BLEU 점수 34.8 기록.
- 기존 SMT 시스템(BLEU 33.3)을 능가.
- 재정렬(Rescoring):
- LSTM으로 SMT 후보 리스트를 재정렬 시 BLEU 점수 36.5 달성.
- 기존 SMT 시스템(33.3) 및 다른 모델(Cho et al.: 34.5)보다 성능 우수.
긴 문장에서의 성능(Long Sentences):

- LSTM은 긴 문장에서도 BLEU 점수 감소가 거의 없었음.
- 입력 시퀀스 역전 처리 덕분에 긴 문장에서도 우수한 번역 성능.
추가분석
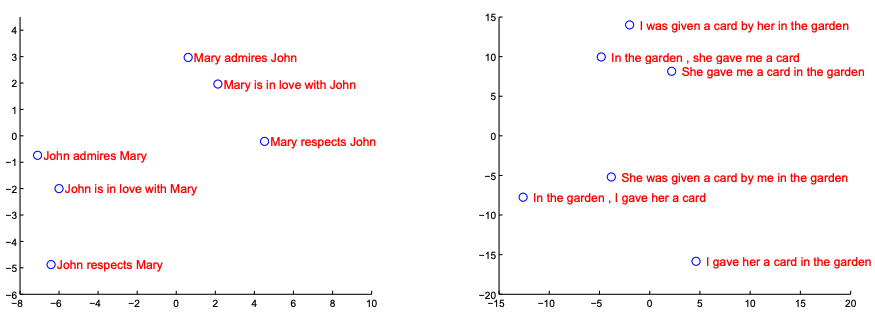
4. Conclusion
이 논문은 LSTM 기반의 시퀀스-투-시퀀스 모델이 기존 통계적 기계 번역(SMT) 시스템을 능가할 수 있음을 보여줌. 특히 입력 시퀀스를 역전시키는 전처리 기법이 모델의 학습을 크게 개선하며, 입력과 출력 간의 단기 의존성을 강화해 최적화를 용이하게 함. 이러한 처리로 인해 LSTM은 긴 문장에서도 성능 저하 없이 우수한 번역 결과를 생성할 수 있었음. WMT’14 영어-프랑스어 번역 작업에서 BLEU 점수 34.8을 기록하며 SMT 시스템(33.3)을 초과함. 또한, 모델은 제한된 어휘와 단순한 구조로도 높은 성능을 보였으며, 번역 품질 향상과 함께 긴 문장을 처리할 수 있는 강력한 메모리 활용 능력을 입증함. 제안된 접근법은 기계 번역을 넘어 다양한 시퀀스 학습 문제에 적용할 가능성이 높으며, 앞으로 추가적인 최적화와 연구를 통해 성능을 더욱 개선할 수 있을 것으로 기대됨.